Back to 2025 Abstracts
Evaluating the Accuracy and Clinical Utility of AI-Generated Responses to Clinical Vignettes in Acute Care Surgery Decision-Making
Issael Gonzalez
*1, Alan Chan
2, Chloe Williams
3, Katherine Bakke
4, Eric Girard
2, Alyson Cunningham
2, Robert J. McLoughlin
21University of Connecticut School of Medicine, Farmington, CT; 2Department of Surgery, University of Connecticut Health Center, Farmington, CT; 3Department of Surgery, UH Cleveland Medical Center, Cleveland, OH; 4Department of Surgery, University of Wisconsin School of Medicine and Public Health, Madison, WI
Background:Artificial intelligence (AI) is increasingly being explored in clinical decision-making, but its accuracy and clinical relevance in surgical settings remain unclear. This study evaluates AI-generated responses to clinical vignettes, assessing alignment with evidence-based surgical guidelines and expert consensus.
Methods:Three large language models (ChatGPT-4, Claude, and OpenEvidence) generated responses to six standardized clinical vignettes representing common acute surgical conditions: appendicitis, cholecystitis, small bowel obstruction, perforated peptic ulcer, and diverticulitis. Five board-certified general surgeons scored blinded responses across four domains: diagnostic accuracy, initial management, definitive management, and postoperative care. Kruskal-Wallis testing was used due to non-normal data distribution, followed by Dunn�s test with Bonferroni correction. Inter-rater reliability was assessed using intraclass correlation coefficients (ICC2) with absolute agreement.
Results:ChatGPT-4 achieved the highest mean scores across all domains, particularly in initial management (mean = 5.47/6) and postoperative care (mean = 4.55/6). Statistically significant differences were observed in initial management (p < 0.001) and postoperative care (p = 0.004), with OpenEvidence scoring significantly lower than both Claude and ChatGPT-4. No significant differences were found in diagnostic accuracy or definitive management.
When converting to percent accuracy, ChatGPT-4 averaged 86.0%, followed by Claude at 83.5% and OpenEvidence at 74.0%. Postoperative care was the lowest-performing domain overall, with OpenEvidence scoring 61.8%. Definitive management showed modest performance, with none of the models exceeding 80%.
Reviewer agreement varied by domain. ICCs indicated slight agreement in diagnosis (ICC = 0.156), moderate agreement in initial management (ICC = 0.493), and fair agreement in definitive management (ICC = 0.248) and postoperative care (ICC = 0.209). Notably, 72.2% of diagnostic scores were identical across all reviewers, suggesting low variability rather than disagreement.
Conclusions:AI models varied in their alignment with clinical standards, with ChatGPT-4 performing the best overall. However, no significant difference was observed between ChatGPT-4 and Claude in post-hoc analysis. Performance dropped in domains requiring greater clinical nuance, particularly initial management and postoperative care. While reviewer agreement was modest, high concordance in diagnostic scoring may reflect consensus. These findings support the potential of AI in surgical decision-making but suggest the need for refinement to ensure reliability across clinical domains.
Inter-Rater Reliability by Clinical Domain (ICC Values and Interpretation)
Clinical Domain
| ICC Value
| Interpretation |
| Diagnosis | 0.156
| Slight |
| Initial Management | 0.493 | Moderate |
Definitive Management
| 0.248 | Fair |
| Postoperative Care | 0.209 | Fair |
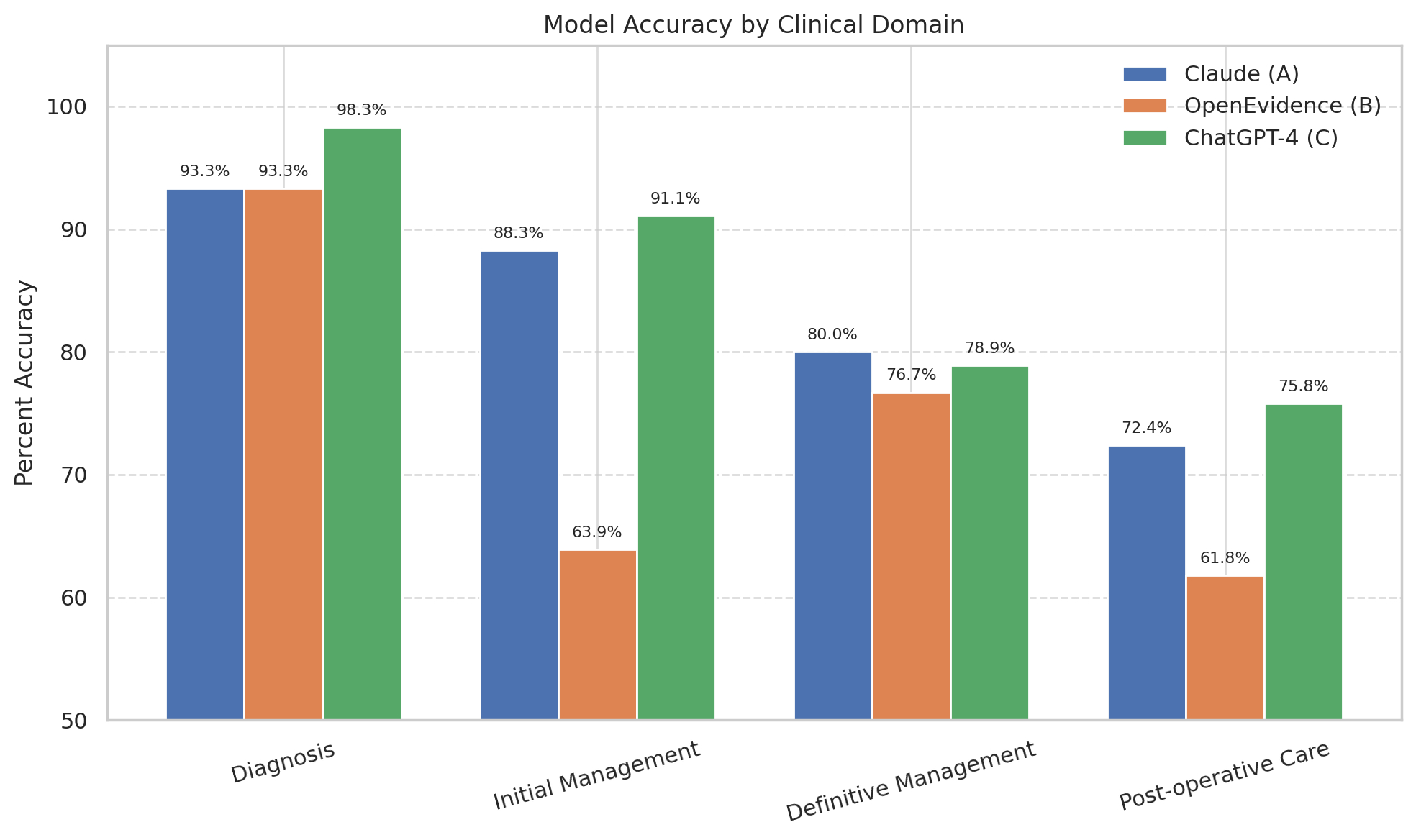
Bar chart showing model response accuracy by clinical domain.


